Better web font loading with JavaScript
Of the many questions we get at Typekit, perhaps the most frequent asks why we require JavaScript to serve fonts.
Typekit is based on the standard CSS @font-face property. But using fonts on the web is about more than just the code we use. Just like video or audio, fonts pose challenges when you need them to work consistently and reliably across the entire ecosystem of browsers and devices. Fonts can also take time to download, and — unlike other kinds of rich media — browsers don’t provide any built-in way to detect when a font has loaded or, more importantly, when it has failed to load. That’s important to know so designers can plan for and apply fallback styles when fonts are unavailable. If a web font fails to load and there’s no fallback, web pages designed around the font can look different, even ugly, and sophisticated web app interfaces can break entirely.
We want to make using web fonts fast, reliable, and — most of all — easy. So to help address some of these challenges we wrap all of our kits in a lightweight JavaScript library that we call Kit JS, which does three things (in this order):
- It identifies the user’s browser, using fast, accurate, client-side detection methods.
- It loads the correct
@font-facerules for that browser by injecting a link to it into the DOM. - Finally, it observes the browser as it loads the fonts themselves, firing font events to provide better control over fallbacks and to help prevent problems like the dreaded flash of unstyled text (or FOUT).
In this post, I’d like to give you a brief introduction to Kit JS, explaining why it’s there and how it works. Let’s get started by first recapping what it is we’re talking about when we talk about “kits.”
Anatomy of a kit
A “kit” is a package of fonts and stylesheets intended for use on a single website or project. After signing up for Typekit, the first thing we ask you to do is create your first (empty) kit, and copy its two-line JavaScript snippet into the of your HTML document:
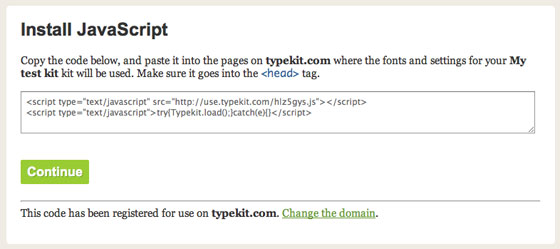
Each kit is easily installed by copying and pasting two lines of Javascript into the of your document.
As I mentioned, a kit is comprised of fonts and stylesheets. Specifically, it consists of:
- Font files for each variation (i.e. weight or style) in your kit, such as Nimbus Sans Extended Light Italic, in every format we support: EOT (for Internet Explorer 8 or earlier), raw TrueType or PostScript fonts (for Safari, iOS, and Android), and WOFF (for everyone else).
- An
@font-facestylesheet covering all of the variations in your kit, for each of the OS/browser combinations we support. For browsers that support it, we embed the actual raw font data directly in the CSS, which helps performance by reducing the number of external requests needed to render the page. - The kit JS file itself, which ties everything together by handling the actual font loading process.
When you publish a kit, all of these items are copied from our library or generated from your kit settings and published as static files to our content delivery network (CDN). A CDN is a network of web servers placed in several regions around the world, each containing a local, cached copy of the kit so users in that region can download kits more quickly.
When a user visits a web page using Typekit fonts, their browser first loads and executes the kit JS file linked from the JavaScript embed code. Then, it detects the user’s browser, and, for IE users, whether or not the browser is in standards or quirks mode. Finally, it kicks off the browser’s default CSS font loading behavior and monitors the process as fonts load, firing font events at each stage along the way. Let’s look at each of these steps.
Fast, scalable browser detection
Because different browsers each support different font formats, it’s necessary for developers to perform some kind of content negotiation to give each browser only the fonts and CSS it can handle. For web fonts, this can be done in one of three ways: using just css, using server-side browser detection, or using client-side browser detection with JavaScript.
Using just CSS
The “bulletproof” @font-face technique uses one stylesheet to link to every available font format, but is written in such a way that each browser will only load the formats it can use. As Chris Coyier wrote back in 2009, “the whole reason that web standards exist is so that we don’t have to write specific code for specific environments.” The bulletproof method is viewed as a web standards-friendly compromise: while it does incorporate some browser-specific hacks, it saves you from having to write, and serve, a different stylesheet for each browser.
The biggest drawback to this method is that it can be brittle: the very same hacks that make it possible to target specific browsers using just CSS may stop working as the browser landscape changes, forcing developers to continually monitor and update their code for regressions that could prevent fonts from loading. This has already happened several times since 2009, and likely will continue to happen for as long as new browsers are being developed.
Using this method you also have less control over which browsers you’re targeting. In one sense this is a feature, not a bug. The bulletproof method isn’t about targeting specific browsers, but rather providing browsers with content in a variety of formats from which they can use whichever is most appropriate. However, when it comes to fonts, the file format is just one part of the story. As we’ve written in the past, every font file contains vector outlines in either TrueType or PostScript format. TrueType outlines are more broadly supported, but some fonts render dramatically better on certain platforms with PostScript outlines. The bulletproof method is effective at delivering fonts in the right file format, but it has no reliable way of delivering different outline formats. For that, you have to use browser detection.
Using server-side browser detection
As the name would imply, browser detection is a kind of content negotiation where different content is served to different users based on information about the browser software they’re using — such as its name, version number, and operating system. It’s frequently executed on a web server, by using the user agent string sent along with every request to identify the browser, then running a simple algorithm to identify and send back the appropriate content. For example, upon receiving a request from someone using Internet Explorer 8, a server set up for this kind of content negotiation would see IE8’s user agent string and decide to send back a stylesheet with fonts in EOT format.
All hosted web font services, including us, use some form of browser detection because it’s more reliable, especially for supporting legacy browsers whose requirements are unlikely to change.
Server-side browser detection has been done on the web for years — in fact, the ability to serve different content to different applications is one reason why the web even has user agent strings. But for our purposes it has several drawbacks, perhaps the biggest of which is that it’s relatively slow. Our font-serving network currently handles about 2,000 requests per second, and running an identifying algorithm on each one of those is very hard to do without affecting performance.
Any time a web browser requests content from a server there is always some delay — or latency — between the moment when a browser submits the request and when the server actually starts sending back a response (that is, the file your browser asked for). During that period browsers are just waiting, and users are left with either a half-rendered page or nothing at all. For web sites to feel fast, latency needs to be as small as possible.
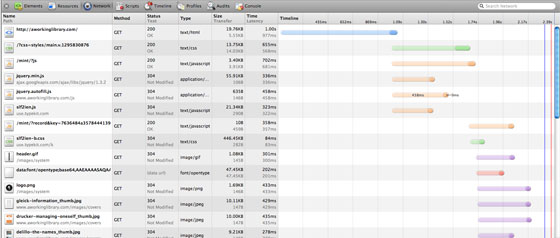
This screenshot from Safari’s Web Inspector shows the effect of latency on page speed. The lighter-shaded segments on the left side of each bar represent latency — time the browser spent waiting for the server to respond to a request — while the darker segments are actual downloading time. The blue bar at the top is the web page itself. In this case, Safari spent 977ms just waiting for the page to begin loading before it could request, load, or display any content.
With regard to serving fonts, there are three main sources of latency:
- Waiting for requests to travel over the network. Servers that are further away will take longer to receive or respond to requests.
- Waiting for a server to perform any tasks it needs to perform before sending the response. This can include authentication, referrer checking, server-side browser detection, or setting up an encrypted connection for SSL-enabled sites.
- Waiting for other users’ requests to finish. If a server is under heavy load, new incoming requests can be put on hold until older requests have been processed.
If you can, imagine a web server as a coffee shop where none of the customers know what they want and the barista has to ask a bunch of questions to help them decide. That’s what server-side detection is like. Browsers request something very generic, like coffee.css, and it’s up to the server to figure out what kind of coffee they need. This is fine as long as the shop isn’t crowded. But when there’s a line, having to go through this negotiation process for every customer will slow things down and frustrate everyone.
Client-side browser detection in JavaScript
But if every customer in line can come in already knowing exactly what they want — not just coffee.css, but black-coffee-with-two-sugars.css — the line moves more quickly. Kit JS allows us to do just that by performing content negotiation on the client side — in the browser itself — which has a number of advantages, not the least of which is speed. Using JavaScript, we can ask each user’s device to identify itself before requesting fonts, then have it only request fonts it can use. Our servers spend less time serving each request, which frees them up to serve more requests quickly, so users can spend time interacting with pages instead of waiting in line for content.
The CSS-based “bulletproof” method also works on the client side, and can have the same speed and scalability advantages. But as I’ve explained, its brittleness makes it harder to work with over time, while JavaScript-based browser detection is more stable. Also, since each browser only receives fonts and styles it can read, there’s no risk of “cross-contamination”: an optimization or hack for one browser is unable to cause problems in another browser, something that can happen with the CSS-only “bulletproof” targeting. As a result, bugs can be traced and isolated to a particular browser faster and more easily.
Another benefit of moving complex logic into the client is CDN compatibility. Publishing kits to a CDN helps us combat latency by pushing kit data to local “edge” servers in various regions around the world. Because many CDN providers have minimal or no support for server-side browser detection, using JavaScript is the only way we can provide a high level of cross-browser support and also take advantage of a CDN’s speed and scale. As a result we’re able to scale our service more easily, and — as a side benefit — offer features for our enterprise customers like the ability to integrate Typekit with their existing CDNs.
Document mode targeting for IE users
Client-side detection is also more accurate. Using JavaScript, we can inspect the browser’s environment to cover scenarios where the standard user agent string is incomplete or misleading.
A great example of this is document mode targeting for newer versions of Internet Explorer. To maintain backward compatibility with older websites that may depend on rendering quirks specific to older versions of IE, newer IEs have the ability to switch into different “document modes” which mimic those older versions’ rendering behavior. In other words, if IE9 detects a web site that’s not compatible with its regular “standards” mode, it will enter a “quirks” mode where it will still identify itself as IE9 in its user agent string but behave as if it were IE7.
This is relevant because older versions of Internet Explorer have several quirks that directly impact font loading and rendering, such as the inability to recognize more than four variations at a time of a single @font-face family. Or worse: if you inadvertently send a WOFF file to IE9 in quirks mode, the font will fail to render at all. In order to best serve fonts to IE9 in quirks mode, we need to be able to detect it and enable features like variation-specific family names. But at the same time, we also want to be able to identify when IE9 is in standards mode, so users can take advantage of its better standards compliance and WOFF support.
The current document mode isn’t referenced anywhere in the IE9 user agent string. JavaScript is the only way to detect it, and by detecting it we can deliver the right fonts reliably to every IE9 user.
Font loading, with font events
Having figured out which fonts to ask for, it’s time for Kit JS to load those fonts. The process for this is pretty simple.
First, the JavaScript constructs a stylesheet URL for the current kit, browser, and OS using the kit ID and information gathered by the browser matcher. These URLs correspond to one of the CSS stylesheet files that were uploaded to our servers when you published your kit. The JS loader then constructs an HTML link tag referencing that URL, and inserts that tag into the web page immediately following the Typekit embed code. You can see the generated link tag for yourself on any site that uses Typekit by using Firebug or the Safari/Chrome Web Inspector to view the web page DOM after fonts have loaded:
http://use.typekit.com/XXXXXXX.js
Here’s an example of the HTML markup our Kit JS inserts into a page that uses Typekit. “XXXXXXX” refers to the unique kit ID, while “ZZZZZZZ” is a cache identifier we use to uniquely identify different published versions of a kit. When you re-publish a kit, this value changes, prompting browsers to re-download the stylesheet.
At this point, your browser has requested and started to load the CSS stylesheet containing your @font-face declarations. The next step is to begin loading the fonts themselves, which ordinarily will happen after the stylesheet has finished loading, as soon as the browser tries to render text that’s been styled with a web font.
Browsers don’t provide any built-in method for detecting when fonts have been loaded or made active on the page, but it would be nice to have this information so we can adjust for differences in font metrics between fallback fonts and web fonts, or prevent an ugly flash of unstyled text. To help work around this limitation, every kit includes our open-source WebFont Loader JavaScript library, which monitors the loading of each individual font variation in your kit, firing font events to let you know how the loading process is going. It works a little bit like this:
- First, the loader fires the “loading” font event, to indicate the process has started. Each time an event is “fired,” the loader sets or changes a CSS class name on the
element corresponding to the name of event. So for the “loading” event, if you inspected your page in Firebug or the Safari/Chrome Web Inspector, you’d see thetag has the class namewf-loading. You can also attach JavaScript callbacks to any font event, to be called when that event is fired. - Next, the loader inserts an invisible HTML
element into the page for each font variation being loaded. Eachis styled with one font variation as well as a special fallback font stack, with metrics different enough from the web font that loading fonts will cause the span’s width to change. Our JavaScript observes the page and watches for this width change to occur, and when it does, the loader fires an “active” font event for that variation. It subsequently removes the span element from the page. If a font variation doesn’t load within five seconds, it’s marked as inactive and the appropriate font event is fired. - Finally, once the loader has tested every variation in the kit, and as long as at least one variation has loaded, the “active” font event is fired for the whole kit. At this point the process is complete, and all fonts that have loaded should now be displayed on your page.
Wrapping up
Web fonts can be tricky things to work with, even beyond issues of browser support and compatibility, or dealing with fallbacks. Hosting font files and delivering them to browsers in a standards-compliant way is important, but it’s just one aspect of a bigger problem. For designers, now that browsers are capable of real typography, getting great fonts into the browser should be the easy part. The real work is in using those fonts to solve typographic problems and make beautiful web sites. The reason we wrap our kits in JavaScript isn’t about browser compatibility, scalability, or preventing the FOUT: it’s to provide a complete, consistent, reliable solution for working with web type — one that any web designer can add to their site with just two lines of code.
3 Responses
Comments are closed.
I think the JavaScript solution that TypeKit uses is great. It’s incredibly easy and intuitive to use, especially for front end developers. The only downside is that it depends on visits having JavaScript enabled in their browser but then I can’t imagine anyone using the web without it enabled these days.
Should the cache identifier (ZZZZZZZ) used in the querystring of the CSS URL be moved out of the querystring and into the file name? If there is a querysting in a static resource, it’s possible that resource is never cached. Having ZZZZZZZ in the filename would still force a re-download but also allow for caching.
See these references:
“According the letter of the HTTP caching specification, user agents should never cache URLs with query strings” – http://carsonified.com/page/147/?cat=6
“Don’t include a query string in the URL for static resources.” – http://code.google.com/speed/page-speed/docs/caching.html
“These query params that cache bust are removed because the filename is revised each time you publish a new version.” – https://github.com/paulirish/html5-boilerplate/wiki/Version-Control-with-Cachebusting
Thankyou for providing such a lucid explanation of the various principles and issues involved.